
近年来,全景图像的全方向空间感知能力使其在计算机视觉领域受到了广泛关注。全景图像为场景理解提供了整个空间结构的语义引导,推动了对弱纹理、无纹理等弱语义场景的空间结构感知与理解,也广泛应用于场景漫游、自动驾驶、AR/VR等领域。

研究者们针对全景图像的球面成像几何模型,将Transformer模型与全景图像相结合,利用Transformer的长距离建模能力提取全景图像的全空间结构信息。然而,现有工作尚未实现全景成像几何模型与Transformer之间的有效耦合,无法充分利用全景空间结构信息来引导Transformer模型重建更精确的整个场景。此外,这些数据驱动模型依赖于难以获取的大规模RGB-D全景数据集以进行训练及参数优化,无法在无深度标注的自监督任务中实现有效的收敛效果。因此,亟需研究与全景成像几何模型结合的Transformer深度学习模型,以挖掘并提高神经网络在自监督任务中的全景图像深度估计与点云重建能力。
近日,肖俊教授团队针对自监督场景下的全景图像深度估计任务取得了新进展,成功地将Transformer模型与全景成像几何模型相结合,以利用全景图像的几何信息引导Transformer模型提取整个场景的全空间结构。同时,提出了一种基于预滤除的新视角图像合成算法,通过合成无混叠图像有效地去除了自监督深度估计结果的边缘伪影。该研究成果实现了高精度的自监督全景深度估计结果,能够广泛地应用于室内、室外等通用场景的重建、理解等任务,对推动全景图像在实际生产生活的进一步推广使用具有重要意义。
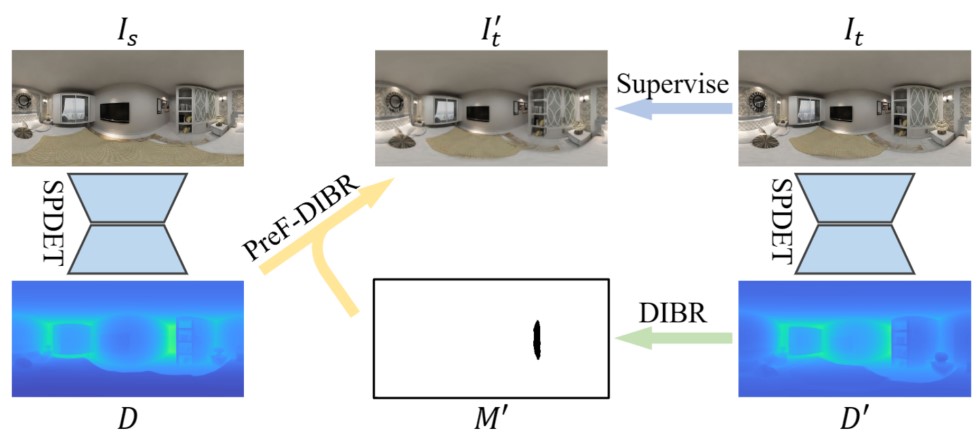
该工作以“SPDET: Edge-Aware Self-Supervised Panoramic Depth Estimation Transformer With Spherical Geometry”为题发表在计算机领域顶级国际期刊《IEEE Transactions on Pattern Analysis and Machine Intelligence》上,中国科学院大学博士生庄传青、博士后卢政达为论文共同一作,肖俊教授为通讯作者。以上工作得到国家自然科学基金委、中科院及国科大等项目的支持。
文章链接:https://doi.org/10.1109/TPAMI.2023.3272949

